1. 奇异值分解(Singular value decomposition)
1.1 基础
矩阵的奇异值分解(SVD)提供了一种三项分解,类似于谱分解,但适用于任何矩阵。通过SVD,我们可以通过矩阵向量乘积y=Ax完整描述与A相关的线性映射,其过程分为三步:首先对输入向量x进行正交变换(旋转(rotation)或反射(reflection));然后对旋转后的输入向量的各元素进行非负缩放,并可能增加或移除该向量的维度以匹配输出空间的维度。最后,在输出空间中进行另一次正交变换。用公式表示为任意矩阵A∈Rm,n都可以分解为
A=UΣ~V⊤
其中V∈Rn,n和U∈Rm,m是正交矩阵(分别描述输入和输出空间中的旋转/反射),并且
Σ~=[Σ0m−r,r0r,n−r0m−r,n−r],Σ=diag(σ1,⋯,σr)≻0
其中r是A的秩,标量σi>0,i=1,⋯,r,表示旋转输入向量上的缩放因子,如下图所示

A的大部分相关特性都可以从其奇异值分解中推导出来。如果我们知道矩阵A的SVD,那么我们也就知道了A的秩、的谱范数(最大增益)以及条件数。此外,我们可以轻松获得A的列空间和零空间的正交基;我们可以求解以A为系数矩阵的线性方程组(参见Section第 6.4.2 节),并分析这些方程中误差的影响;我们还可以求解超定线性方程组的最小二乘解,或者欠定系统的最小范数解
1.2 奇异值分解定理
我们在这里陈述奇异值分解定理,并随后给出一个示意性证明
定理5.1(奇异值分解):任何矩阵A∈Rm,n都可以分解为
A=UΣ~V⊤
其中V∈Rn,n和U∈Rm,m是正交矩阵(即U⊤U=Im,V⊤V=In)并且Σ~∈Rm,n矩阵前r:=rankA个对角线元素(σ1,⋯,σr)为正且按大小递减,其余所有元素为零
证明
考虑矩阵A⊤A∈Sn。该矩阵是对称的且半正定,它可以进行谱分解
A⊤A=VΛnV⊤
其中V∈Rn,n是正交矩阵(即V⊤V=In),Λn是对角矩阵,对角线上包含特征值λi=λi(A⊤A)≥0,i=1,⋯,n,按降序排列。由于r=rankA=rankA⊤A,这些特征值中前r个是严格正的。注意AA⊤和A⊤A具有相同的非零特征值,因此秩也都为r
- rankA=rankA⊤A
第一步:N(A)⊆N(A⊤A)
Ax=0⇒A⊤Ax=0,证明完毕
第二步:N(A⊤A)⊆N(A)
A⊤Ax=0⇒x⊤A⊤Ax=0,令y=Ax
y⊤y=∥y∥22=0,可得y=0,即Ax=0,证明完毕
第三步:秩的等式推导
最终有N(A⊤A)=N(A),根据定理3.1知
rankA+dimN(A)=nrankA⊤A+dimN(A⊤A)=n
因此rankA=rankA⊤A
同理可证rankA⊤=rankAA⊤,于是rankA⊤=rankA=rankAA⊤=rankA⊤A
- A⊤A的前r个特征值严格为正
实对称矩阵可正交对角化
V⊤A⊤AV=Λn=diag(λ1,⋯,λn)
由于V为正交矩阵,故其可逆。可知任何一个可逆矩阵都可以分解成一连串初等矩阵的乘积且初等变换不会改变矩阵的秩。因此Λn的秩也为r,由于对角矩阵的秩为对角线上非零元素的个数,因此A⊤A的前r个特征值严格为正
- AA⊤与A⊤A有相同的非零特征值
第一步:若λ是A⊤A的非零特征值,则也是AA⊤的特征值
根据特征值定义
A⊤Ax=λx,λ=0,x=0
两边左乘A
AA⊤Ax=λAx
令y=Ax
AA⊤y=λy
因为y=0,因此λ也是AA⊤的特征值
第二步:若λ是AA⊤的非零特征值,则也是A⊤A的特征值
证明过程同上
综上,AA⊤与A⊤A非零特征值完全相同,仅特征值的重数可能因矩阵阶数不同而有差异因为AA⊤和A⊤A的阶数不同
因此我们可以定义
σi:=λi(A⊤A)=λi(AA⊤)>0,i=1,⋯,r
现在,将V的前r列记为v1,⋯,vr,即A⊤A与λ1,⋯,λr相关的特征向量。根据定义
A⊤Avi=λivi,i=1,⋯,r
因此,两边同时乘以A
AA⊤Avi=λiAvi,i=1,⋯,r
这意味着Avi,i=1,⋯,r是AA⊤的特征向量。这些特征向量是互相正交的,因为
vi⊤A⊤Avj=λjvi⊤vj={λi0if i=jotherwise
因此,归一化向量
ui=λiAvi=σiAvi,i=1,⋯,r
形成一组与非零特征值λ1,⋯,λr相关的标准正交向量集合。然后,对于i=1,⋯,r
ui⊤Avj=σi1vi⊤A⊤Avj=σiλjvi⊤vj={σi0if i=jotherwise
用矩阵形式重写前面的关系可以得到
u1⊤⋮ur⊤A[v1⋯vr]=diag(σ1,⋯,σr):=Σ
这已经是SVD的紧凑形式。接下来我们将推导SVD的完整版本。根据定义
A⊤Avi=0,i=r+1,⋯,n
这意味着
Avi=0,i=r+1,⋯,n
为了验证后一种说法,通过反证法假设A⊤Avi=0且Avi=0。则Avi∈N(A⊤)≡R(A)⊥,这是不可能的,因为显然Avi∈R(A)。那么,我们可以找到正交单位向量ur+1,⋯,um使得u1,⋯,ur,ur+1,⋯,um构成Rm的一组正交基,那么
ui⊤Avj=0,i=1,⋯,m;j=r+1,⋯,n
综合两种情况,我们可以得到
u1⊤⋮um⊤A[v1⋯vm]=[Σ0m−r,r0r,n−r0m−r,n−r]:=Σ~
定义正交矩阵U=[u1,⋯,um] 后,表达式可重写为U⊤AV=Σ~,在左侧乘以U、右侧乘以V⊤后,最终得到完整的SVD分解
A=UΣ~V⊤
V由A⊤A的标准正交特征向量组成,因此V∈Rn,n;U由AA⊤的标准正交特征向量组成,因此U∈Rm,m
推论5.1(紧凑型SVD):任何矩阵A∈Rm,n都可以表示为
A=i=1∑rσiuivi⊤=UrΣVr⊤
其中r=rankA,Ur=[u1,⋯,ur]满足Ur⊤Ur=Ir,Vr=[v1,⋯,vr]满足Vr⊤Vr=Ir,并且σ1≥σ2≥⋯σr>0。正数σi称为A的奇异值(singular value),向量ui称为A的左奇异向量(left singular vector),vi称为右奇异向量(right singular vector)。这些量满足
Avi=σiui,A⊤ui⊤=σivi,i=1,⋯,r
此外,σi2=λi(AA⊤)=λi(A⊤A),i=1,⋯,r且ui是AA⊤的特征向量;vi是A⊤A的特征向量
2. 通过奇异值分解的矩阵性质
在本节中,我们回顾矩阵A∈Rm,n的若干性质,这些性质可以直接从其完整形式的奇异值分解(SVD)中得出
A=UΣ~V⊤
或紧凑形式的奇异值分解中得出
A=UrΣVr⊤
2.1 秩、零空间和值域
矩阵A的秩r是非零奇异值的数量,即Σ~对角线上非零元素的数量。此外,由于在实际中Σ~对角元素可能非常小但不完全为零(例如,存在数值误差),可以定义一个更可靠的数值秩,其定义为在给定容差ϵ≥0的情况下,使σk>ϵσ1的最大k
由于r=rankA,根据线性代数基本定理,A的零空间的维数为dimN(A)=n−r。一个跨越N(A)的标准正交基由V的最后n−r列给出,即
N(A)=R(Vnr),Vnr:=[vr+1,⋯,vn]
为了证明这一点,vr+1,⋯,vn形成一个标准正交向量组(它们是一个正交矩阵的列)。此外,对于位于Vnr范围内的任意向量ξ=Vnrz,我们有
Aξ=UrΣVr⊤Vnrz=0
类似地,A值域的标准正交基由U的前r列给出
R(A)=R(Ur),Ur:=[u1,⋯,ur]
为了证明这一点,首先注意到,由于ΣVr⊤∈Rr,n,且r≤n,是满行秩的,那么当x遍历整个Rn空间时,z=ΣVr⊤x张成整个Rr空间,因此
R(A)={y:y=Ax,x∈Rn}={y:y=UrΣVr⊤x,x∈Rn}={y:y=Urz,z∈Rr}≡R(Ur)
2.2 矩阵范数
矩阵A∈Rm,nFrobenius范数的平方可以定义为(乘以正交矩阵不会改变Frobenius范数)
∥A∥F2=traceA⊤A=i=1∑nλi(A⊤A)=i=1∑nσi2
其中σi是A的奇异值。因此,Frobenius范数的平方是奇异值平方的和
矩阵谱范数平方等于A⊤A的最大特征值
∥A∥22=∥u∥2=1max∥Au∥22=∥u∥2=1maxu⊤A⊤Au=σ12
也就是说,A的谱范数与A的最大奇异值相同
此外,矩阵A的所谓核(nuclear)范数(也叫迹范数)是通过其奇异值来定义的
∥A∥∗=i=1∑rσi,r=rankA
可逆矩阵A∈Rn,n的条件数(condition number)定义为其最大奇异值与最小奇异值的比值
κ(A)=σnσ1=∥A∥2⋅∥A−1∥2
这里逆矩阵的特征值可见下一节,该数值提供了A接近奇异的量化衡量(κ(A) 越大,A 越接近奇异)。条件数还提供了线性方程组解对方程系数变化的敏感性度量,参见第Section6.5节
2.3 矩阵伪逆(pseudoinverse)
给定任意矩阵A∈Rm,n,令r=rankA,并对其进行SVDA=UΣ~V⊤。所谓的Moore-Penrose伪逆(或广义逆(generalized inverse))定义为
A†=VΣ~†U⊤∈Rn,m
其中
Σ~†=[Σ−10n−r,r0r,m−r0n−r,m−r],Σ−1=diag(σ11,⋯,σ1r)≻0
上式也可以写出简洁形式
A†=VrΣ−1Ur⊤
根据定义有
Σ~†Σ~=[Ir0n−r,r0r,n−r0n−r,n−r],Σ~Σ~†=[Ir0m−r,r0r,m−r0m−r,m−r]
由此伪逆具有以下性质
AA†=UrUr⊤A†A=VrVr⊤AA†A=AA†AA†=A†
注意以下三种特殊情况
- 如果A是方阵且非奇异,则A†=A−1
- 如果A∈Rm,n列满秩,即r=n≤m,那么此时V为方阵,满足正交
A†A=VrVr⊤=VV⊤=In
也就是说,在这种情况下,A†是A的左逆(即一个矩阵,当在左侧乘以A†时,会得到单位矩阵:A†A=In)。注意,在这种情况下A⊤A是可逆的,我们有
(A⊤A)−1A⊤=(VrΣ−2Vr⊤)VrΣ⊤Ur⊤=VrΣ−2ΣUr⊤=VrΣ−1Ur⊤=A†
A的任何可能的左逆都可以表示为
Ali=A†+Q⊤
其中Q是某个矩阵,使得A⊤Q=0(即Q的列属于A⊤的零空间)。综上所述,在列满秩的情况下,伪逆是A的左逆,并且可以用A写出出具体的表达式
A∈Rm,n,r=rankA=n≤m⇒A†A=In,A†=(A⊤A)−1A⊤
- 如果A∈Rm,n是行满秩,即r=m≤n,那么此时U为方阵,满足正交
AA†=UrUr⊤=UU⊤=Im
也就是说,在这种情况下,A†是A的右逆(即,当它在右侧与A相乘时,会得到单位矩阵AA†=Im)。注意,在这种情况下AA⊤可逆,我们有
A⊤(AA⊤)−1=VrΣ⊤Ur⊤(UrΣ−2Ur⊤)⊤=VrΣ−1Ur⊤=A†
A的任何可能的右逆都可以表示为
Ari=A†+Q
其中Q是某个矩阵,使得AQ=0(即Q的列属于A的零空间)。综上所述,在行满秩的情况下,伪逆是A的右逆,并且可以用A写出出具体的表达式
A∈Rm,n,r=rankA=m≤n⇒AA†=Im,A†=A⊤(AA⊤)−1
2.4 正交投影算子
我们已经看到,任何矩阵A∈Rm,n都定义了输入空间Rn与输出空间Rm 之间的线性映射y=Ax。此外,根据线性代数的基本定理,输入空间和输出空间可分解为正交分量,如下所示
Rn=N(A)⊕N(A)⊥=N(A)⊕R(A⊤)Rm=R(A)⊕R(A)⊥=R(A)⊕N(A⊤)
如前所述,SVDA=UΣ~V⊤为这四个子空间提供了标准正交基
U=[UrUnr],V=[VrVnr]
其中Ur,Vr分别包含U和V的前r=rankA列,我们有
N(A)=R(Vnr),N(A)⊥≡R(A⊤)=R(Vr)R(A)=R(Ur),R(A)⊥≡N(A⊤)=R(Unr)
接下来我们讨论如何计算向量x∈Rn在N(A),N(A)⊥上的投影,以及向量y∈Rm在R(A),R(A)⊥上的投影
首先,我们回顾一下,给定一个向量x∈Rn和d个线性无关的向量b1,⋯,bd∈Rn,x在由{b1,⋯,bd}张成的子空间上的正交投影是向量
x∗=Bα
其中B=[b1,⋯,bd]而α需要通过解线性方程组得到
B⊤Bα=B⊤x
上述方程请参考Section2.3节。特别注意,如果B中的基向量是标准正交的(注意此时B并不一定是方阵,因此它并不一定是正交矩阵),那么有B⊤B=Id,因此线性方程组有一个直接解α=B⊤x,投影可以简单地计算为x∗=BB⊤x
回到我们感兴趣的情况,设x∈Rn,并且假设我们想要计算x在N(A)上的投影。由于N(A)的一组标准正交基由Vnr的列给出,根据前面的推理,我们可以立即得到
[x]N(A)=(VnrVnr⊤)x
我们使用符号[x]S来表示向量x在子空间S上的投影。现在,注意到
In=VV⊤=VrVr⊤+VnrVnr⊤
因此
PN(A)=VnrVnr⊤=In−VrVr⊤=In−A†A
矩阵PN(A)被称为投影到子空间N(A)的正交投影算子。在A为行满秩的特殊情况下,A†=A⊤(AA⊤)−1,那么
PN(A)=In−A⊤(AA⊤)−1A,A为行满秩
通过类似的推理,我们得到x∈Rn在N(A)⊥≡R(A⊤)上的投影由下式给出
[x]N(A)⊥=(VrVr⊤)x=PN(A)⊥x,PN(A)⊥=A†A
特殊情况下
PN(A)⊥=A⊤(AA⊤)−1A,A为行满秩
类似地,对于y∈Rm,我们有
[y]R(A)=(UrUr⊤)y=PR(A)y,PR(A)=AA†PR(A)=A(A⊤A)−1A⊤,A为列满秩[y]R(A)⊥=(UnrUnr⊤)y=PR(A)⊥y,PR(A)⊥=Im−AA†PR(A)⊥=Im−A(A⊤A)−1A⊤,A为列满秩
子空间上的投影。我们考虑计算给定向量y∈Rm投影到由给定向量集S=span(a(1),⋯,a(n))⊆Rm所生成子空间的问题,正如在第Section 2.3 节和第 5.2 节中已经讨论的那样。显然,S与将这些向量作为列的矩阵A:=[a(1),⋯,a(n)]的列空间相一致,因此我们面临的问题是
z∈R(A)min∥z−y∥2
如果r:=dimS=rank(A),那么A的紧凑形式奇异值分解为A=UrΣVr⊤,并且上式的唯一最小范数解由投影定理给出为
z∗=[y]S=PR(A)y=AA†y=(UrUr⊤)y
其中PR(A)是到R(A)的正交投影算子。注意到投影z∗是y的线性函数,并且定义该投影的矩阵由ASVD的Ur因子提供
类似地,假设我们想要找到y在S⊥上的投影,即S的正交补。由于S⊥=N(A⊤),该问题可写为
z∈N(A⊥)min∥z−y∥2
方程的解为
z∗=[y]S⊥=(Im−AA†)y
3. 奇异值分解与优化
在本节中,我们将说明如何通过奇异值分解方便地解决某些优化问题。SVD在优化中的进一步应用将在Section第六章中介绍
3.1 低秩矩阵近似(Low-rank matrix approximations)
设A∈Rm,n是一个给定矩阵,且rank(A)=r>0。这里我们考虑用低秩矩阵近似A的问题。具体来说,我们考虑以下秩受限近似问题
Ak∈Rm,nmin∥A−Ak∥F2s.t. :rank(Ak)=k
其中1≤k≤r是给定的。令
A=UΣ~V⊤=i=1∑rσiuivi⊤
为A的SVD。接下来我们将证明,上述问题的最优解可以通过将前面的求和截断到第k项来简单获得,即
Ak=i=1∑kσiuivi⊤
为了证明上述低秩近似结果,注意到Frobenius范数是幺正不变(unitarily
invariant)的,这意味着对于所有Y∈Rm,n以及任意正交矩阵Q∈Rm,n,R∈Rm,n,都有∥Y∥F=∥QYR∥F。因此
∥A−Ak∥F2=∥U⊤(A−AkV)∥F2=∥Σ~−Z∥F2
其中Z=U⊤AkV,通过变量变换,问题可以表述为
Z∈Rm,nmin[diag(σ1,⋯,σr)0m−r,r0r,n−r0m−r,n−r]−ZF2s.t. :rank(Z)=k
注意,初等变换不会改变矩阵的秩。可以假设Z是对角矩阵,因为考虑Z中的非零非对角元素只会使该问题中的Frobenius范数目标变差。因此,目标变为
f0=∥diag(σ1,⋯,σr)−diag(z1,⋯,zr)∥F2=i=1∑r(σi−zi)2
由于约束条件rank(Z)=k要求对角线上恰好k个元素zi非零,最好的选择是设置zi=σi,i=1,⋯,k并且zi=0,i>k。通过这种方式,前k个zi中和了A的最大奇异值,使得目标中的剩余项仅包含r−k个最小奇异值,即一个最优解为
Z∗=[diag(σ1,⋯,σk,0,⋯,0)0m−r,r0r,n−r0m−r,n−r]
最优的目标为
f0∗=i=k+1∑rσi2
原问题的最优解可以通过变量变换Z=U⊤AkV恢复,得到
Ak=UZ∗V⊤=i=1∑kσiuivi⊤
这确实与我们猜测的一致。按照完全相同的推理,我们实际上可以证明,这个解不仅对于Frobenius范数目标是最优的,对于谱矩阵范数(最大奇异值)也是最优的。也就是说,Ak对于以下问题也是最优的(谱范数同样是幺正不变的)
Ak∈Rm,nmin∥A−Ak∥22s.t. :rank(Ak)=k
比率
ηk=∥A∥F2∥Ak∥F2=σ12+⋯+σr2σ12+⋯+σk2
表示A的秩为k的近似在多大程度上解释了A的总方差(Frobenius范数)。显然,ηk与相对范数近似误差有关
ek=∥A∥F2∥A−Ak∥F2=σ12+⋯+σr2σk+12+⋯+σr2=1−ηk
备注5.2(到秩亏的最小距离):假设A∈Rm,n,m≤n,且满秩,即rank(A)=n。我们想知道使A+δA变为秩亏(非满秩)的最小扰动δA。最小扰动的Frobenius范数(或谱范数)衡量了A到秩亏的距离。形式上,我们需要解
δA∈Rm,nmin∥δA∥F2s.t. :rank(A+δA)=n−1
这个问题等价于低秩矩阵近似,其中δA=Ak−A。因此解可以很容易得到为
δA∗=Ak−A
其中A=∑i=1nσiuivi⊤是A的紧凑型奇异值分解并且Ak=∑i=1n−1σiuivi⊤,因此,我们有
δA∗=−σnunvn⊤
这个结果表明,导致秩亏的最小扰动是一个秩为一的矩阵,而且到秩亏的距离为∥δA∗∥F=∥δA∗∥2=σn
3.2 主成分分析(Principal component analysis)
主成分分析是一种无监督学习技术,广泛用于发现数据集中最重要或最具信息量的方向,也就是数据变化最大方向
考虑下图中的二维数据云:沿着大约45度方向几乎包含了数据的所有变化。相比之下,沿着大约135度方向包含的数据变化很少。这意味着,在这个例子中,数据背后的重要现象本质上沿着45度的方向是一维的。当分析维度大于3的数据时,图形直觉就无济于事,这时主成分分析就显得很有用
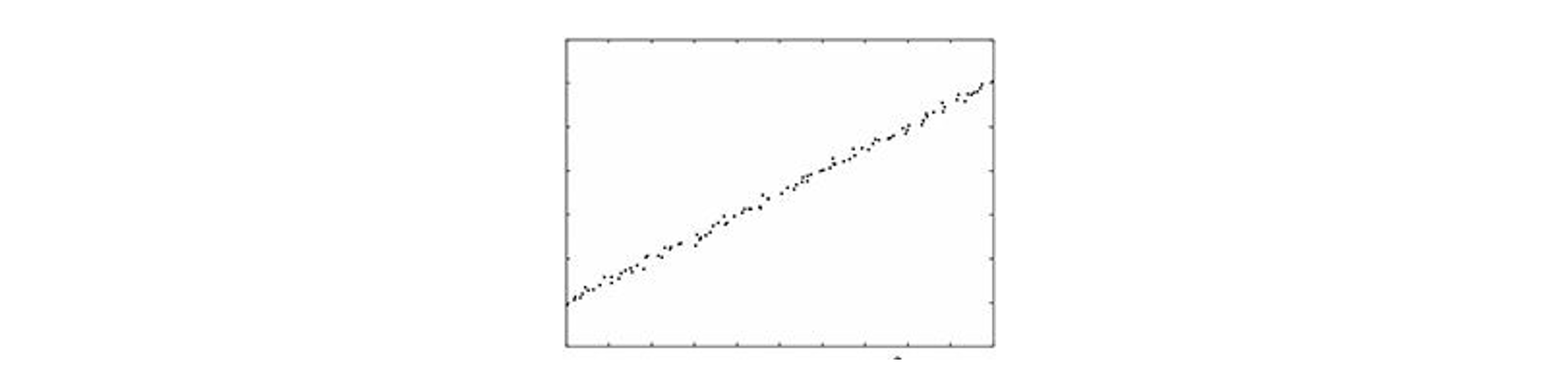
设xi∈Rn,i=1,⋯,m为希望分析的给定数据点,记数据点的平均值为xˉ=m1∑i=1mxi,并设X~是n×m阶矩阵并包含居中后的数据点
X~=[x~1⋯x~m],x~i:=xi−xˉ,i=1,⋯,m
我们在数据空间中寻找一个归一化方向z∈Rn,满足∣z∣2=1,使得中心化数据点在由z决定的直线上的投影方差最大。我们选择在 z的归一化中使用欧几里得范数,是因为它不会偏向任何特定方向
沿z方向的中心化数据的分量由下式给出(参见Section例如第 2.3.1 节)
αi=x~i⊤z,i=1,⋯,m
注意,αi z 是 i 在 z 的张成空间上的投影。沿着方向 z 的数据均方变化由此给出
未完待续